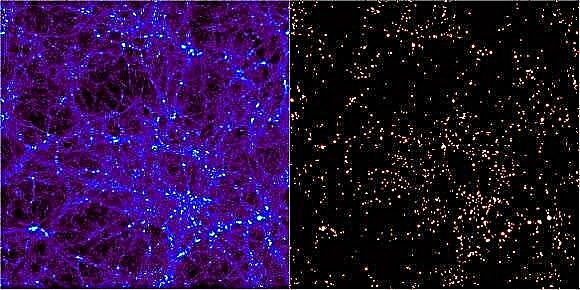
Одним из успехов модели вселенной ΛCDM является способность моделей создавать структуры с масштабами и распределениями, аналогичными тем, которые мы видим в космическом журнале. Хотя компьютерное моделирование может воссоздать числовые вселенные в одном окне, интерпретация этих математических приближений сама по себе является сложной задачей. Чтобы идентифицировать компоненты моделируемого пространства, астрономы должны были разработать инструменты для поиска структуры. В результате было получено около 30 независимых компьютерных программ с 1974 года. Каждая из них обещает раскрыть формирующуюся структуру во вселенной путем поиска областей, в которых образуются ореолы темной материи. Чтобы протестировать эти алгоритмы, в мае 2010 года в Мадриде, Испания, была организована конференция под названием «Haloing going MAD», на которой 18 из этих кодов были проверены, чтобы увидеть, насколько хорошо они сложились.
Числовые симуляции вселенных, такие как знаменитая симуляция тысячелетия, начинаются только с «частиц». Хотя они, несомненно, были небольшими в космологическом масштабе, такие частицы представляют собой сгустки темной материи с миллионами или миллиардами солнечных масс. Поскольку время идет вперед, им разрешается взаимодействовать друг с другом в соответствии с правилами, которые совпадают с нашим лучшим пониманием физики и природы такой материи. Это приводит к развивающейся вселенной, из которой астрономы должны использовать сложные коды, чтобы найти конгломераты темной материи, внутри которых будут образовываться галактики.
Один из основных методов, используемых такими программами, заключается в поиске небольших плотностей и последующем выращивании сферической оболочки вокруг нее, пока плотность не упадет до незначительного значения. Большинство из них затем обрезают частицы внутри объема, которые не связаны гравитационно, чтобы убедиться, что механизм обнаружения не просто захватил кратковременную кратковременную кластеризацию, которая развалится во времени. Другие методы включают в себя поиск в других фазовых пространствах частиц с близкими скоростями (знак того, что они стали связанными).
Чтобы сравнить, как прошел каждый из алгоритмов, они прошли два теста. Первый, включал в себя серию намеренно созданных гало темной материи со встроенными субгало. Поскольку распределение частиц было сделано намеренно, выходные данные программ должны правильно определять центр и размер ореолов. Второе испытание было полноценной симуляцией вселенной. При этом фактическое распределение не будет известно, но сам по себе размер позволит сравнивать разные программы с одним и тем же набором данных, чтобы увидеть, насколько сходным образом они интерпретируют общий источник.
В обоих тестах все искатели в целом работали хорошо. В первом тесте были некоторые расхождения, основанные на том, как разные программы определяли расположение ореолов. Некоторые определяли его как пик плотности, в то время как другие определяли его как центр масс. При поиске субгало, те, которые использовали подход фазового пространства, казалось, могли более надежно обнаруживать меньшие образования, но не всегда обнаруживали, какие частицы в скоплении были фактически связаны. Для полной симуляции все алгоритмы согласованы исключительно хорошо. Из-за характера моделирования малые масштабы не были хорошо представлены, поэтому понимание того, как каждая из них обнаруживает эти структуры, было ограниченным.
Комбинация этих тестов не отдавала предпочтение одному конкретному алгоритму или методу перед любым другим. Выяснилось, что каждый в целом функционирует хорошо по отношению друг к другу. Возможность для очень многих независимых кодов с независимыми методами означает, что результаты чрезвычайно надежны. Знания, которые они передают о том, как развивается наше понимание вселенной, позволяют астрономам проводить фундаментальные сравнения с наблюдаемой вселенной, чтобы проверить такие модели и теории.
Результаты этого теста были собраны в документ, который планируется опубликовать в следующем выпуске Ежемесячных уведомлений Королевского астрономического общества.